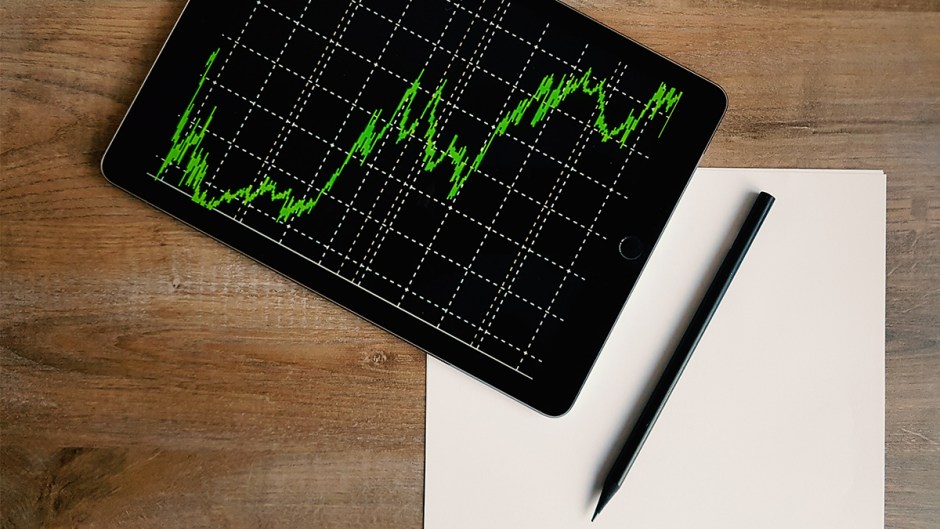
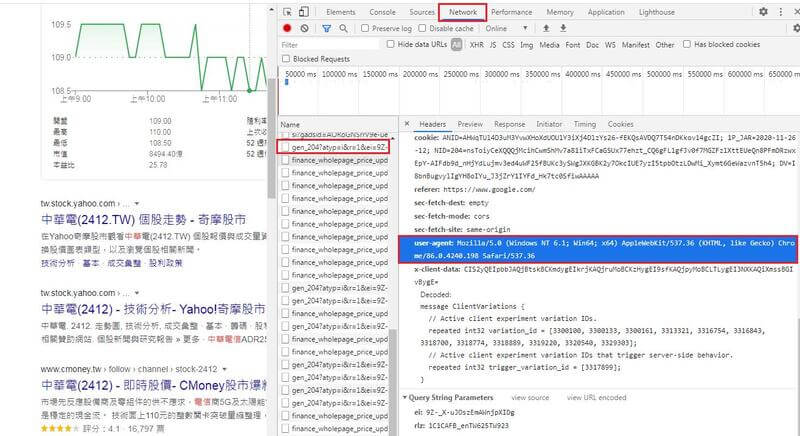
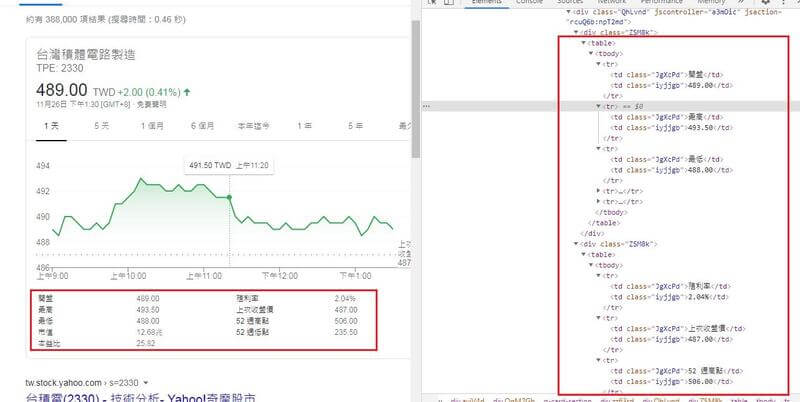
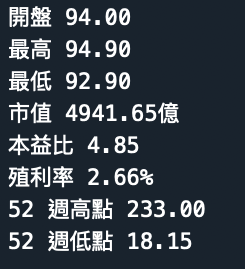
# 第4個 g-card-section, 有左右兩個 table 分別存放股票資訊 for table in sections[3].find_all(‘table’): for tr in table.find_all(‘tr’)[:3]: #[:3] 取得3個字 key = tr.find_all(‘td’)[0].text.lower().strip() #lower()轉小寫。 strip()去除頭尾空 value = tr.find_all(‘td’)[1].text.strip() stock[key] = value
return stock
if __name__ == ‘__main__’: page = get_stock_page(targetURL, ‘2603’)
if page: stock = get_stock_info(page) for k, v in stock.items(): print(k, v)